How does MySQL 5.7 InnoDB In-Memory data structures work?
by aaronchenwei
MySQL maintains an in-memory cache for high throughput and low latency. On dedicated servers, around 80% of memory is utlized by in-memory caching layer to support high-volume read operations.
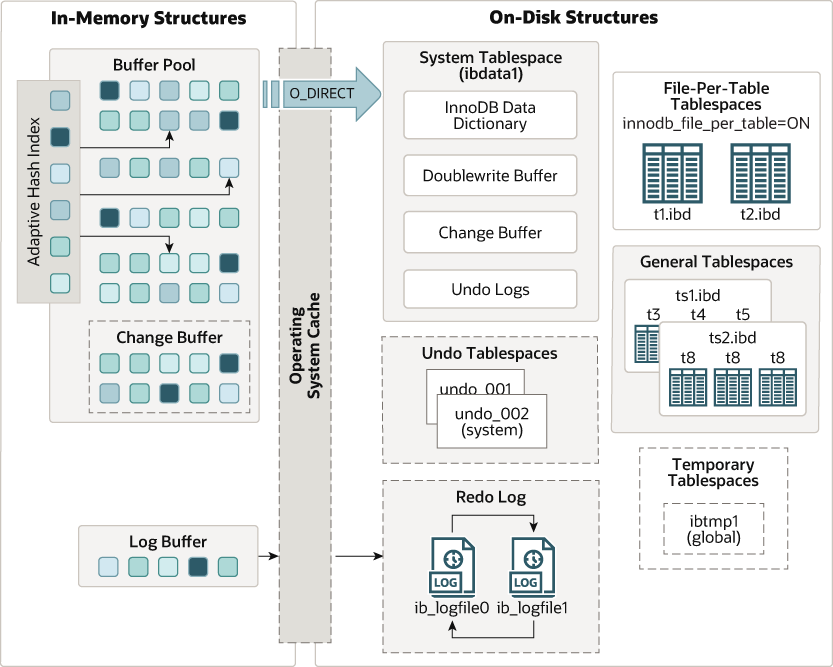
The components of in-memory data structures are the following
Buffer Pool
- The buffer pool is an area in main memory where the INNODB caches the table and index data as it is accessed.
- In MySQL, data is stored in pages. Pages can contain multiple rows. Buffer pool maintains a linked list of pages.
- The data that is rarely used is aged out of the cache using a variation of LRU algorithm.
- Buffer Pool LRU algorithm
- A single linked list is divided into two sub-lists i.e young sub-list and old sub-list. Young sub-list is basically 5/8 size of pool while old is 3/8 of size of pool.
- A newly accessed page by either user-query or read ahead is inserted in the head of old sub-list.
- Young sub-list contains most recently accessed while old sub-list contains most recently accessed pages.
- Accessed page gets transferred to young sub-list. Pages not accessed since long reaches the tail of old sub-list and are eventually evicted.
Change Buffers
- Change buffer caches changes to the secondary index pages when those indexes are not in buffer pool.
- These buffered changes may arise from insert, update and delete operations. They are later merged when the pages are loaded into buffer pool through read operations.
- Overall process of change buffer
- Cache changes to secondary indexes not in buffer pool in change buffer.
- Periodically write cached index pages to disk.
- Changes are merged as soon as secondary indexes are loaded into the buffer pool.
- Why change buffers stress on secondary indexes change caching?
- Reads, writes, deletes and updates on secondary indexes are random as compared to clustered indexes. They are not present adjacently and it is difficult to load so much data into buffer pool.
- To save the cost of expensive I/O, changes to secondary indexes are cached in change buffers. These changes are either later flushed to disk or merged when secondary index data is loaded into buffer pool.
Adaptive Hash Index
- This enables INNODB to behave like an in-memory database with correct combination of workloads and buffer pool size without sacrificng transactional features.
- Based on the observed pattern of searches, INNODB builds a hash index from the prefix of an already indexed key. It is built on demand for the pages of the index that are accessed often.
- INNODB has to maintain a balance between the cost of monitoring the search pattern and benefit of read queries from building an hash index.
Log Buffer
- It is the memory area where data to be written to log files on disk is stored temporarily.
- A large log buffer enables large transactions to run without the need to write to redo log data to disk before the transactions commit.
- If you have high write throughput, increasing the log buffer size will save disk I/O.